Just another WordPress site
Just another WordPress site

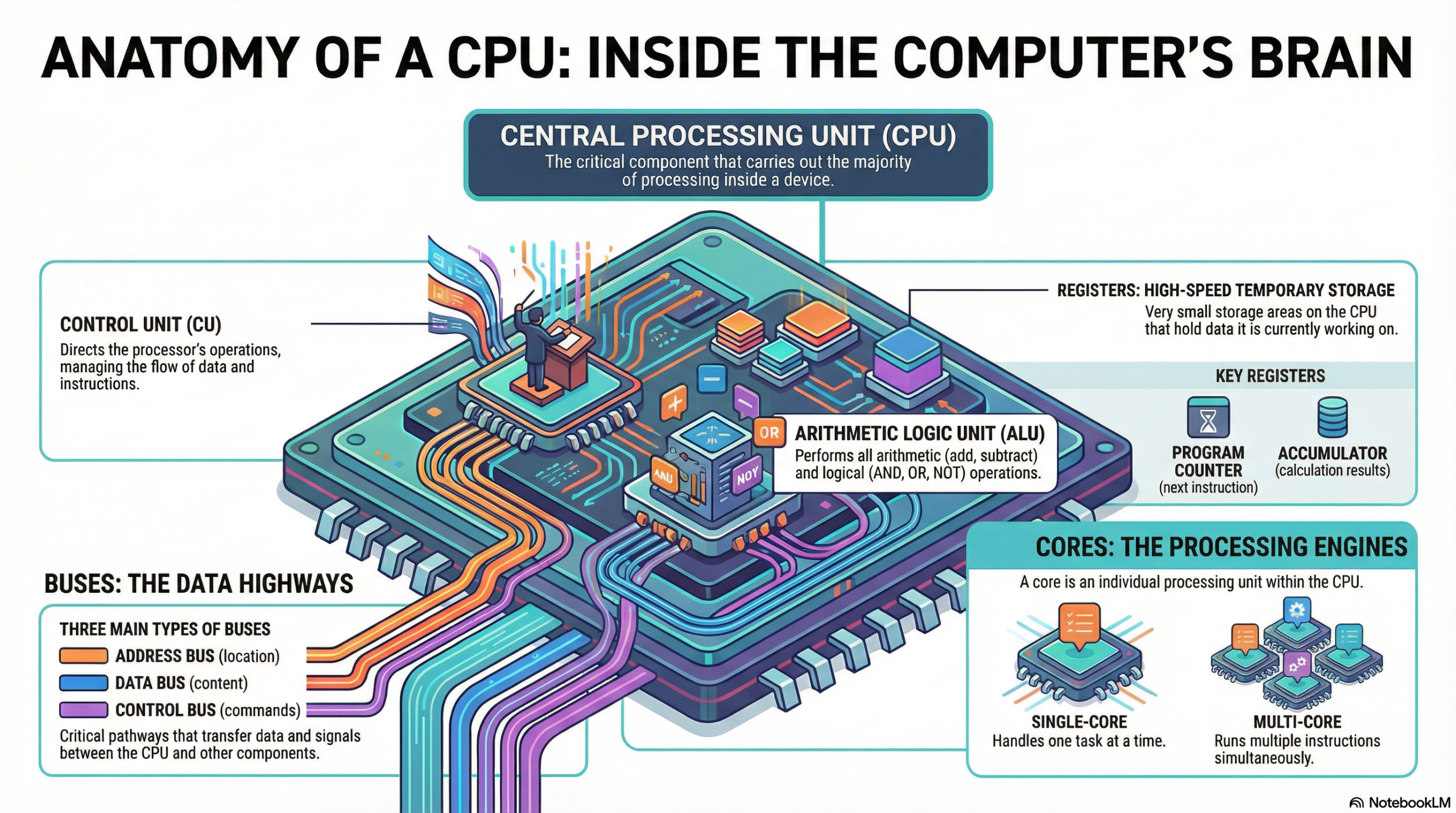
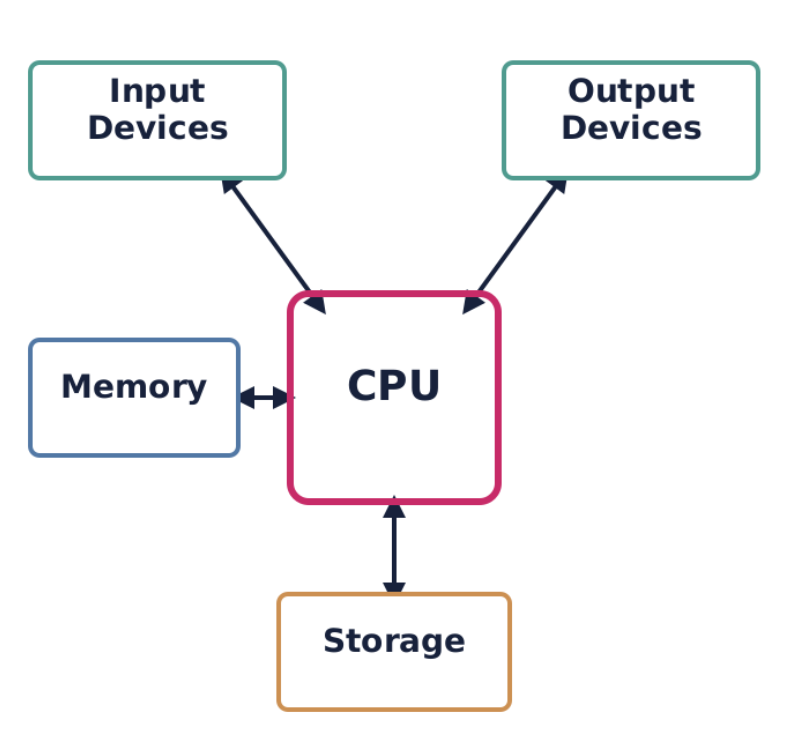
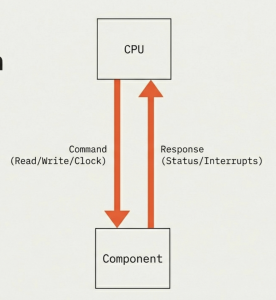
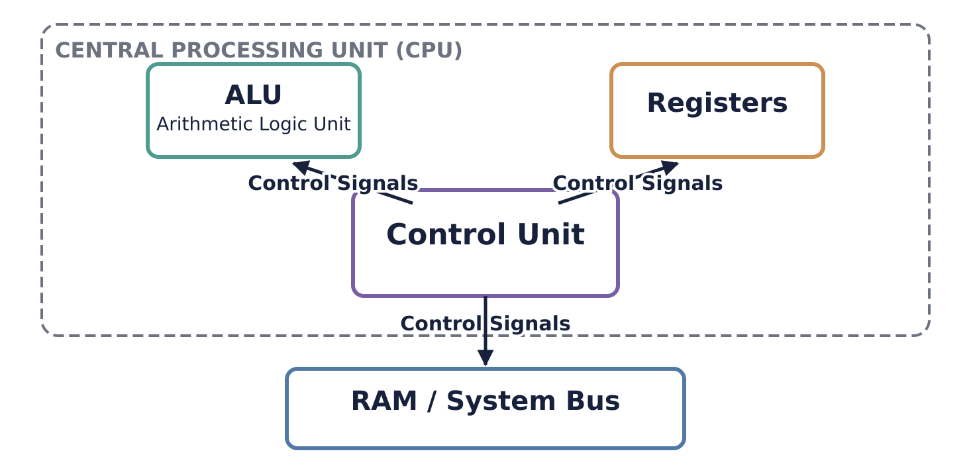
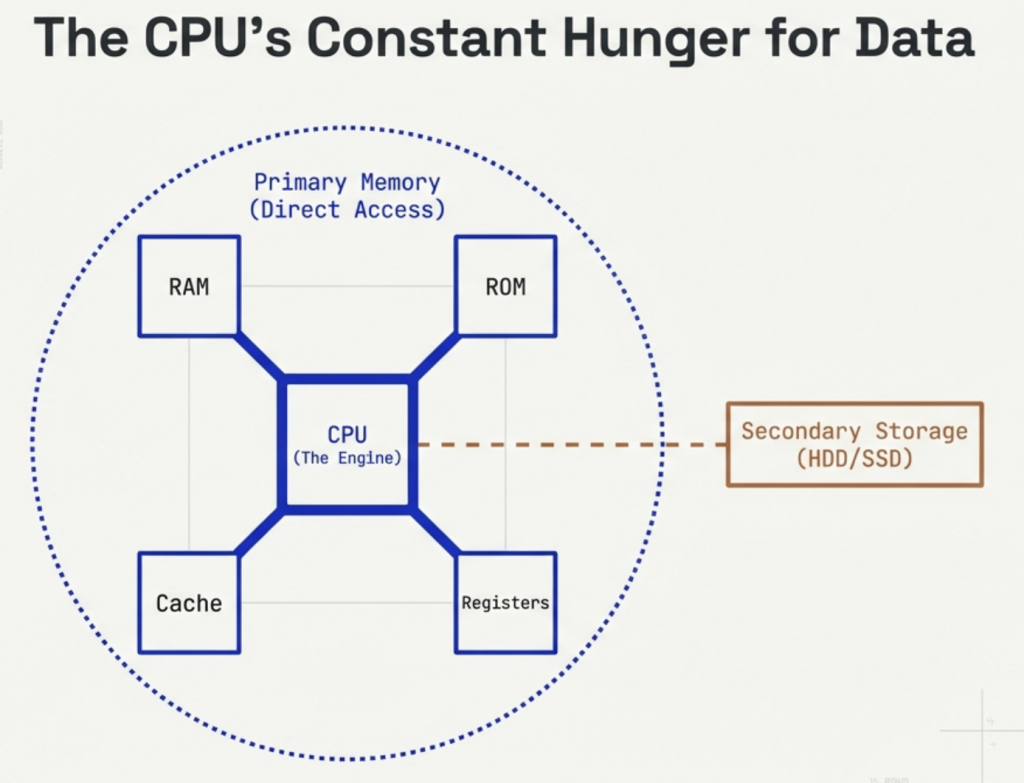
The CPU’s primary role is to process data by carrying out instructions. These instructions are fundamental operations like adding two numbers, moving data from one location to another, or making a decision based on a comparison. Every action a computer takes, from opening an application to displaying an image, ultimately breaks down into a series of instructions that the CPU executes.
For instance, when a user clicks an icon to launch a web browser, the operating system translates that click into a series of instructions. These instructions might include:
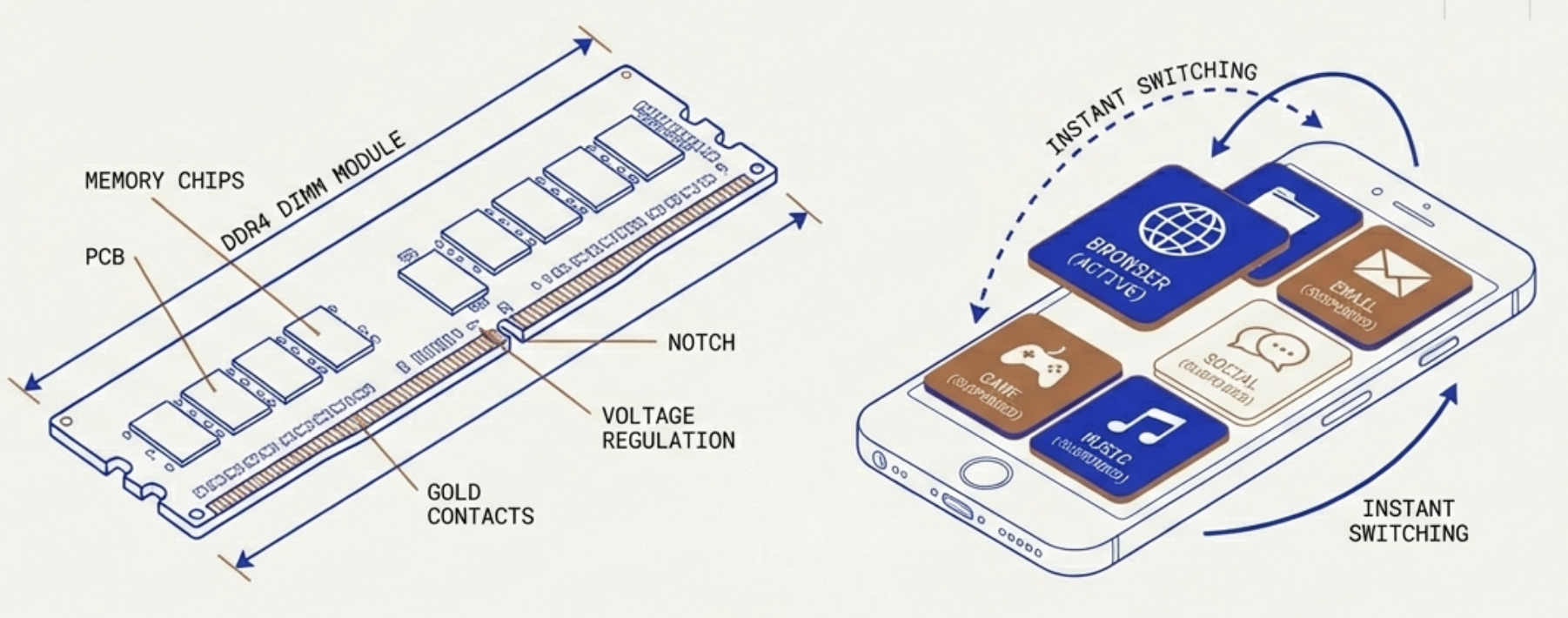
Loading the browser’s program code from storage (e.g., SSD) into main memory (RAM).
Allocating memory space for the browser process.
Initializing various browser components.
Beginning to fetch instructions for rendering the browser window.
Another example occurs when a user types a character on the keyboard. The CPU receives an interrupt signal indicating keyboard input. It then executes instructions to:
Read the scan code from the keyboard controller.
Translate the scan code into a character (e.g., ASCII or Unicode).
Store the character in a buffer.
Display the character on the screen by sending instructions to the graphics card.
A hypothetical scenario might involve a simple embedded system controlling a smart thermostat. When the thermostat detects the room temperature has dropped below a set point, the CPU executes instructions to:
Read the current temperature sensor value.
Compare it to the desired temperature set point.
If below the set point, send a command to the heating system to turn on.
Continuously monitor the temperature until it reaches the set point, then send a command to turn the heating off.
Real-World Application
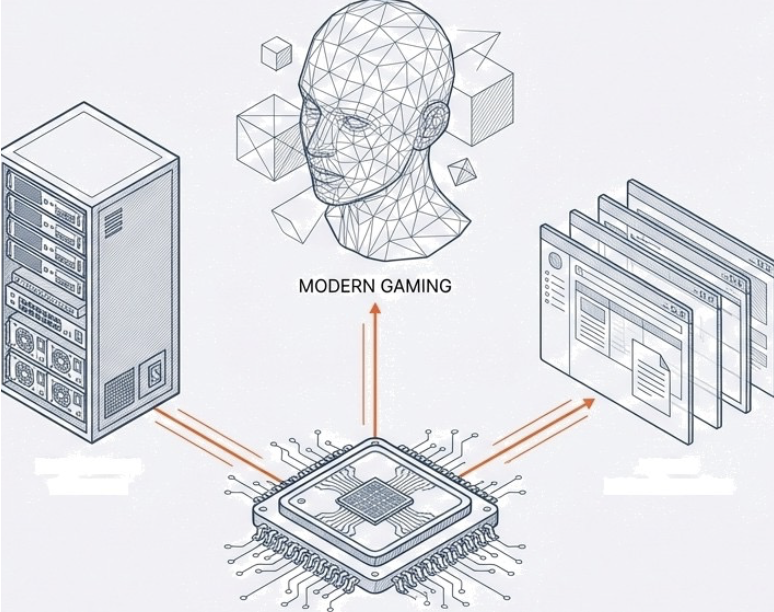
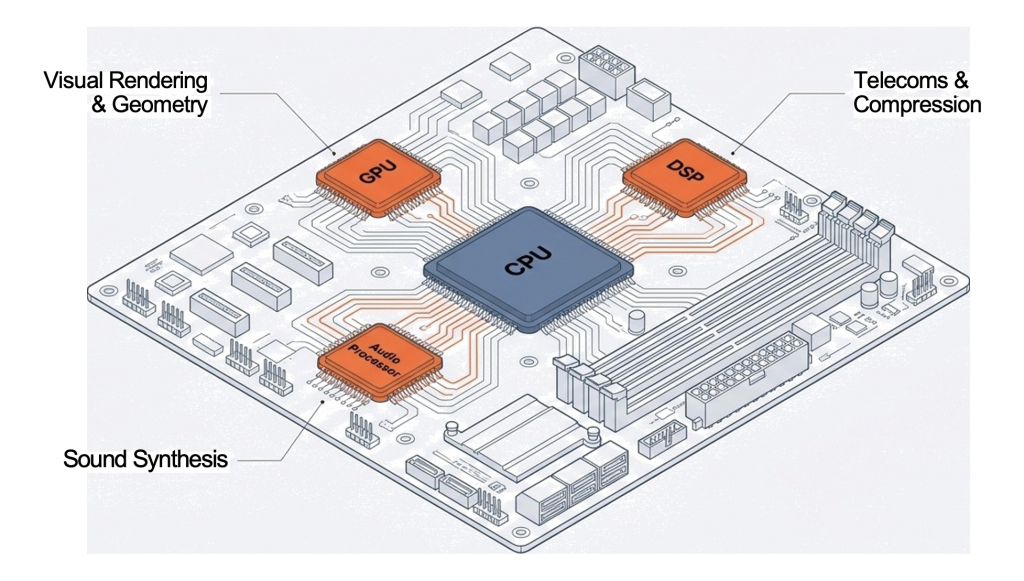
Modern CPUs are incredibly complex, but their high-level function remains consistent across various applications. In data centers, massive server CPUs manage millions of transactions per second for online services. Each transaction involves fetching instructions for database queries, processing data, and often sending results across a network. Similarly, in your smartphone, a low-power CPU manages background apps, processes touch inputs, and orchestrates communication with cellular and Wi-Fi radios. The core principle of fetching instructions, processing data, and interacting with other components holds, regardless of scale or specific application. The efficiency and speed of these high-level interactions are paramount for overall system performance, whether in a supercomputer or a tiny embedded device.


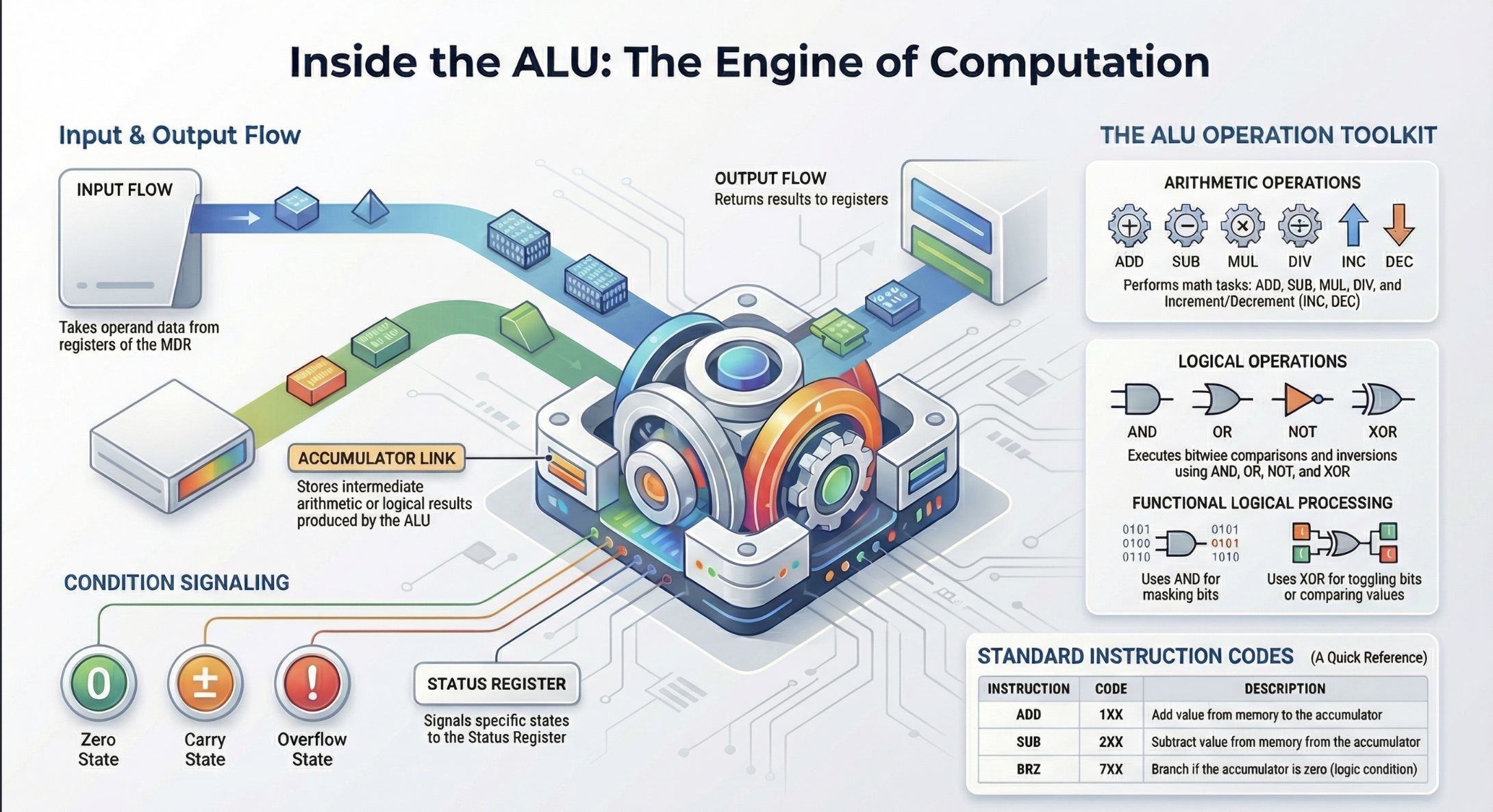
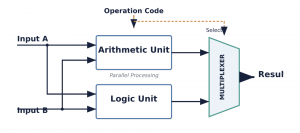
Shift Operations:
Logical Shift Left/Right: Shifts bits to the left or right, filling vacated positions with zeros. Used for efficient multiplication or division by powers of 2.
Arithmetic Shift Right: Shifts bits to the right, preserving the sign bit. Used for signed integer division by powers of 2.
Rotate Left/Right: Shifts bits, but bits that “fall off” one end are inserted at the other end.
Comparison Operations:
CMP: Compares two operands by performing an internal subtraction and updating the flags register, but without storing the result. This allows subsequent conditional jump instructions to make decisions based on the comparison (e.g., JG—Jump if Greater).

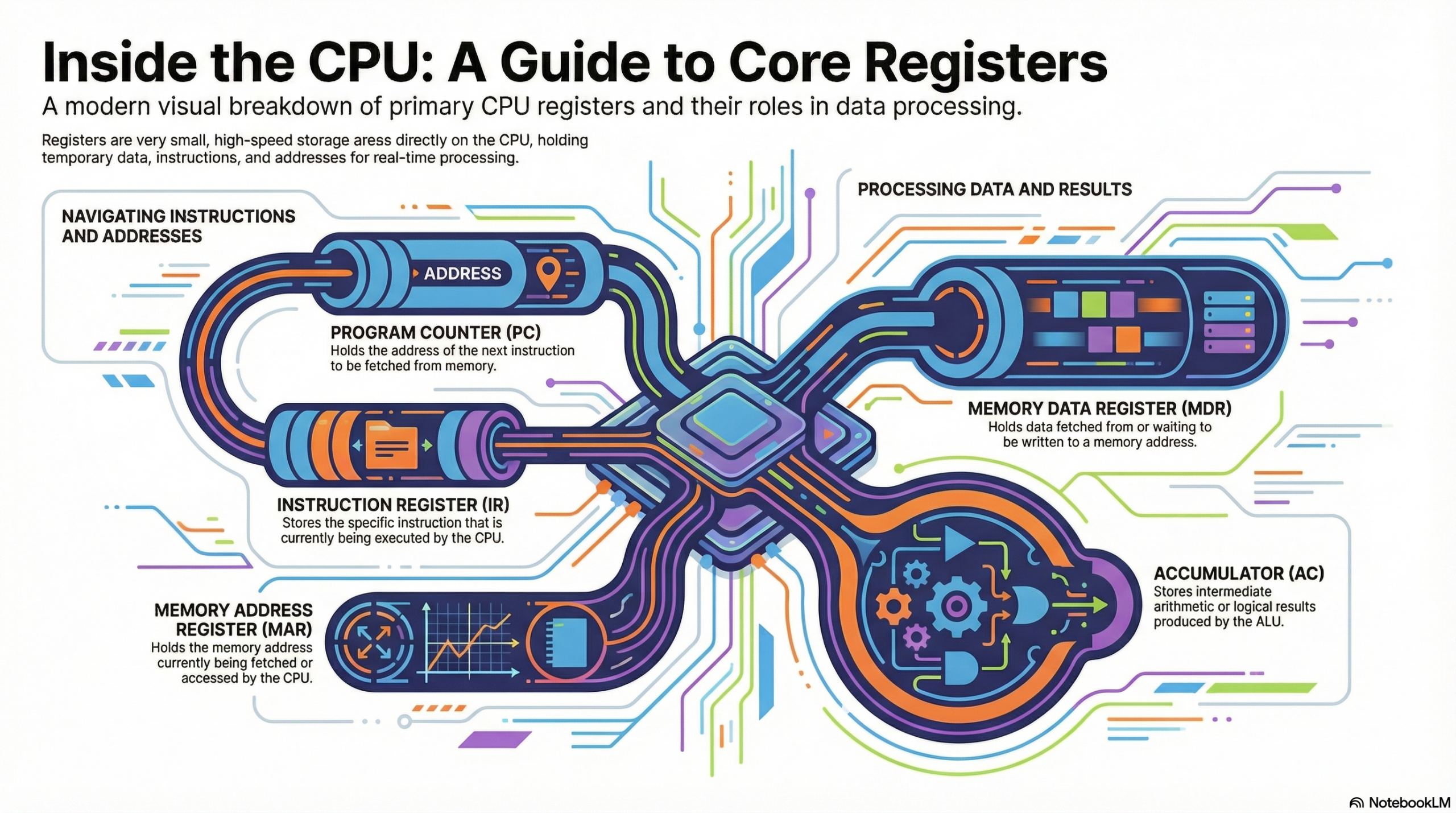
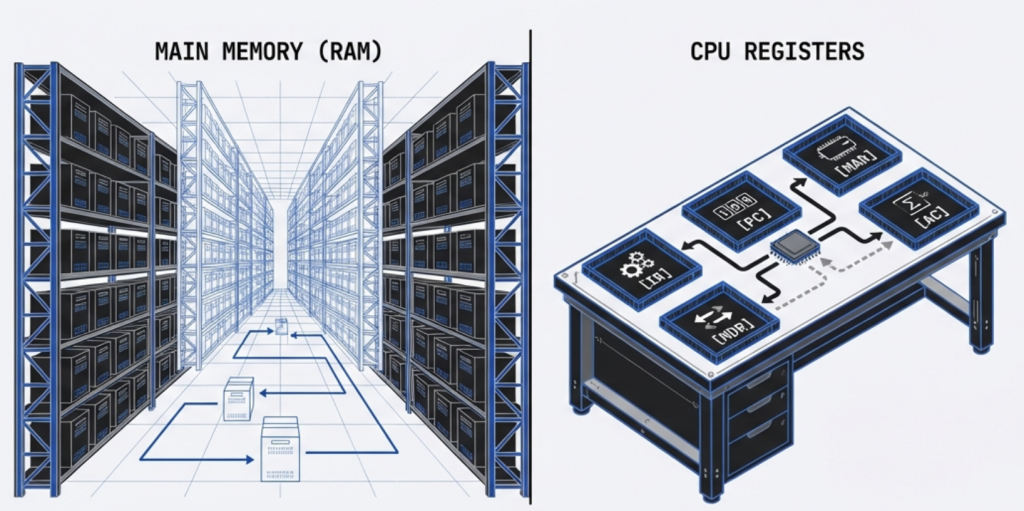

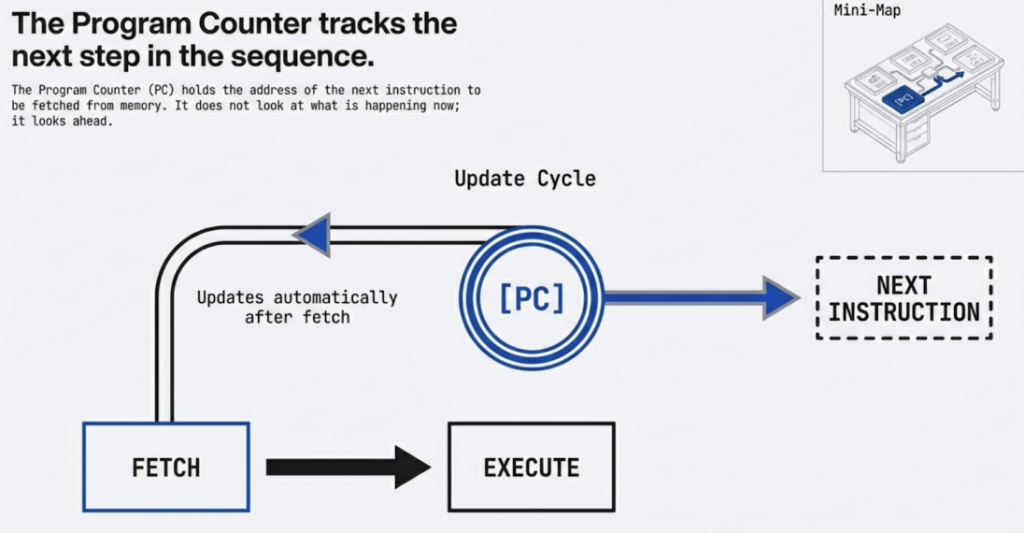
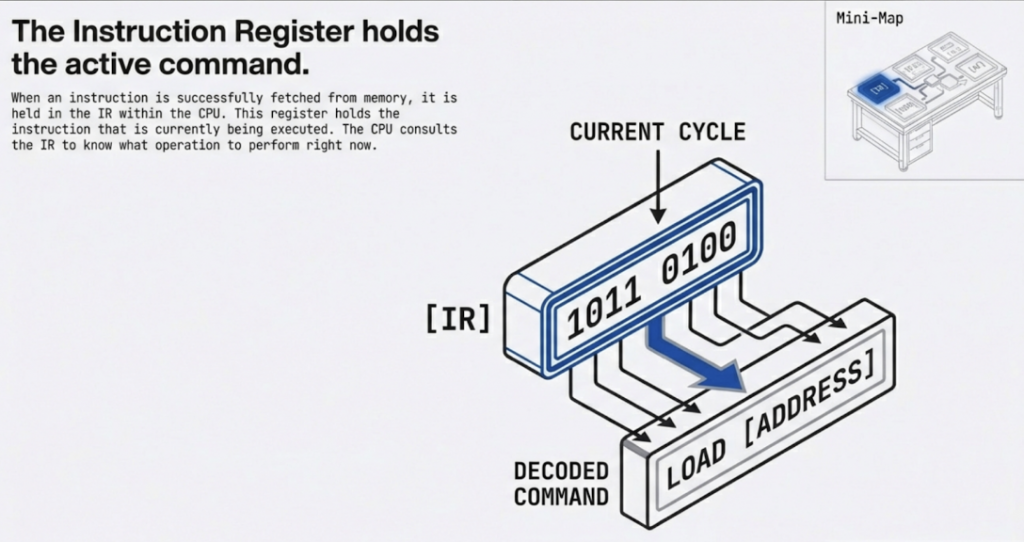
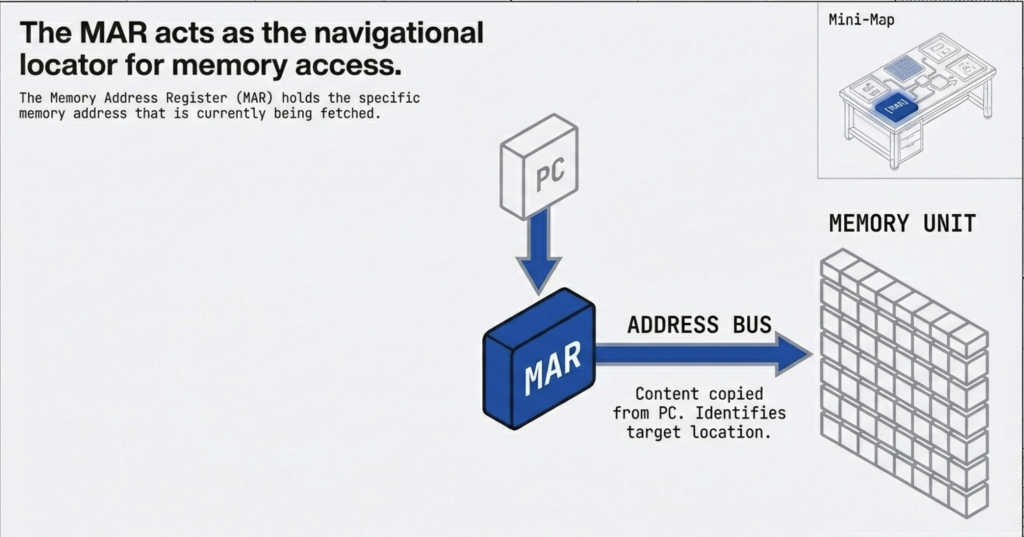
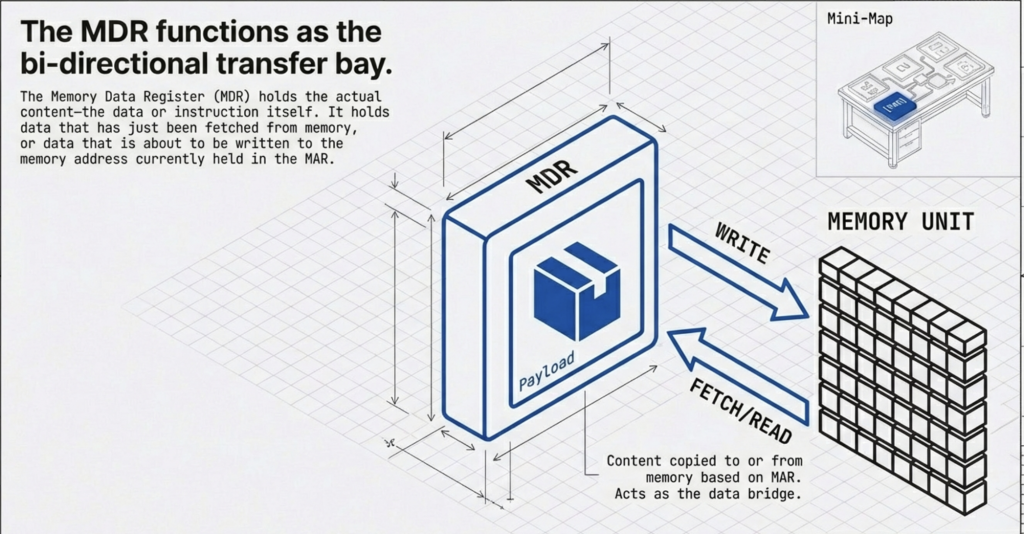
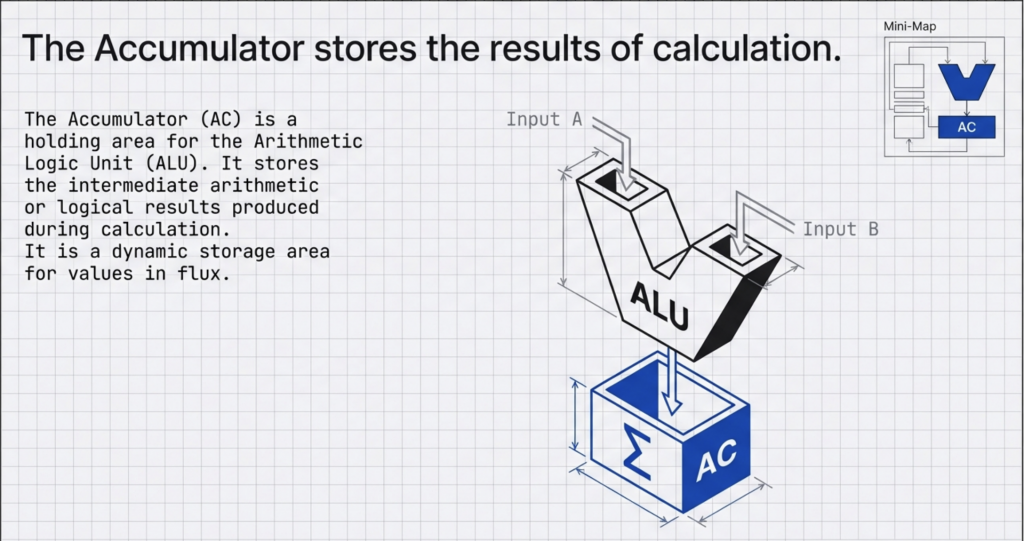
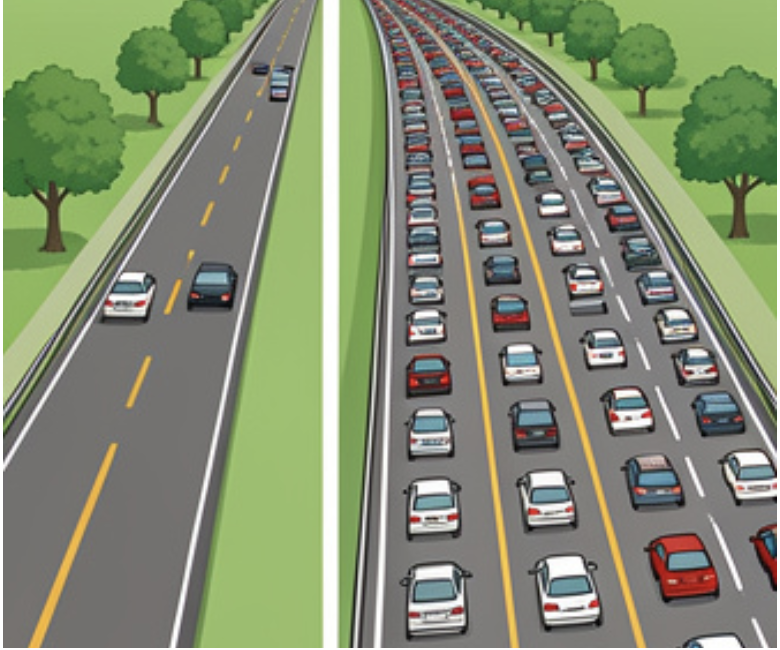




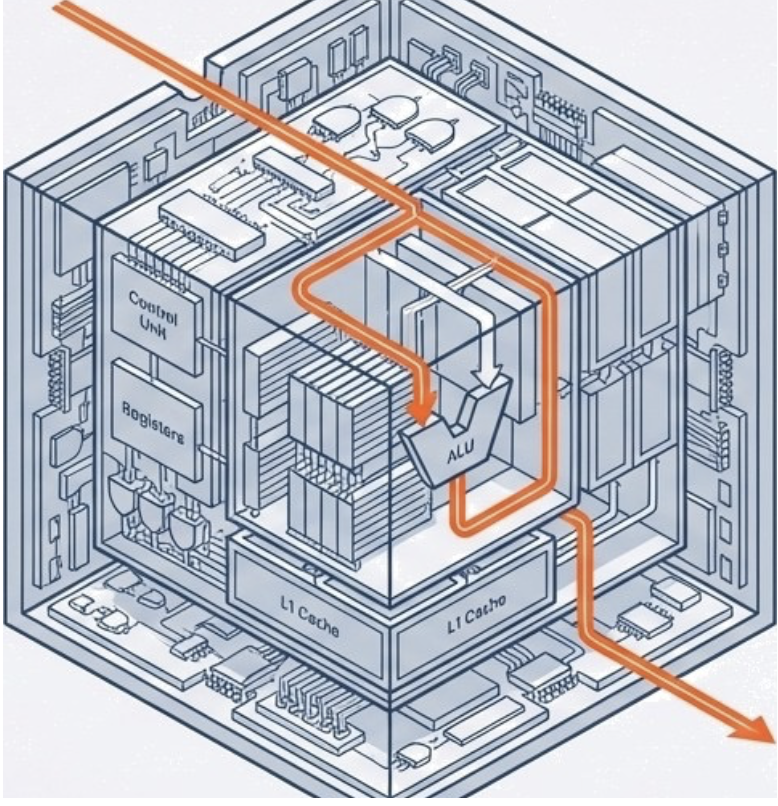
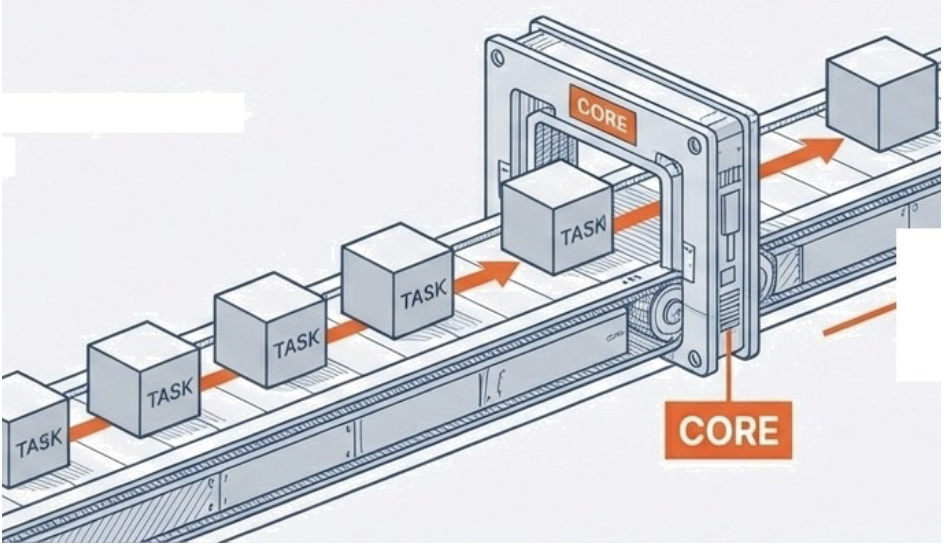
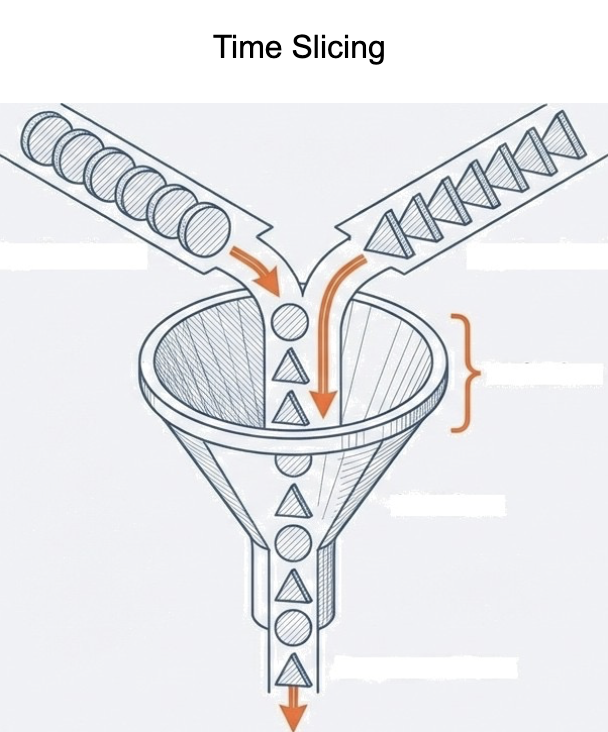
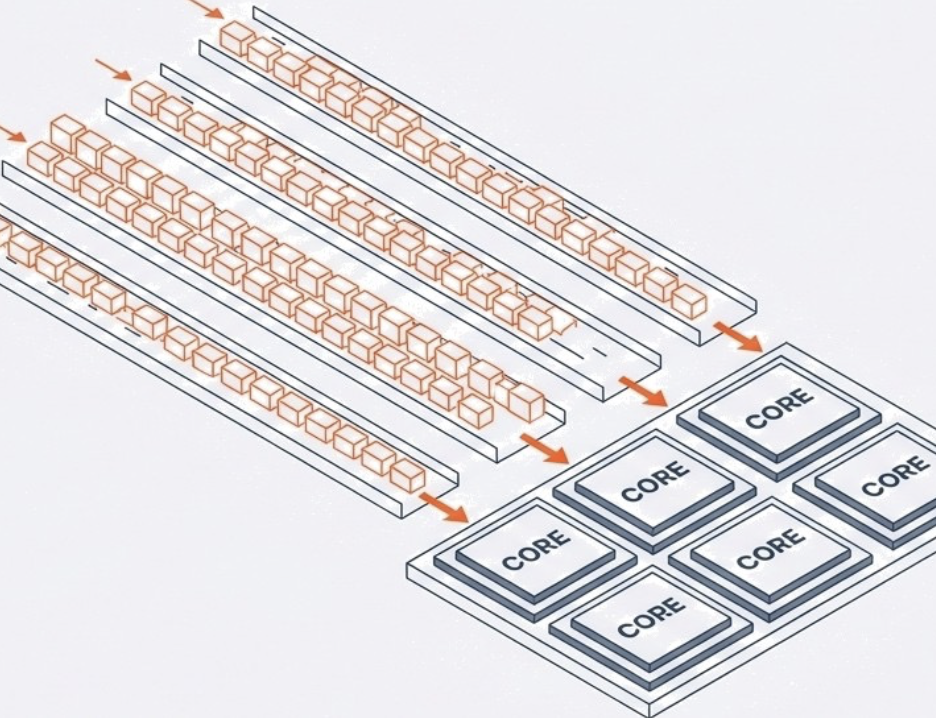
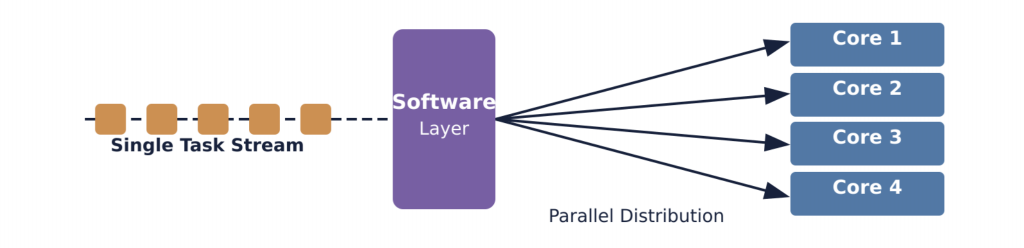
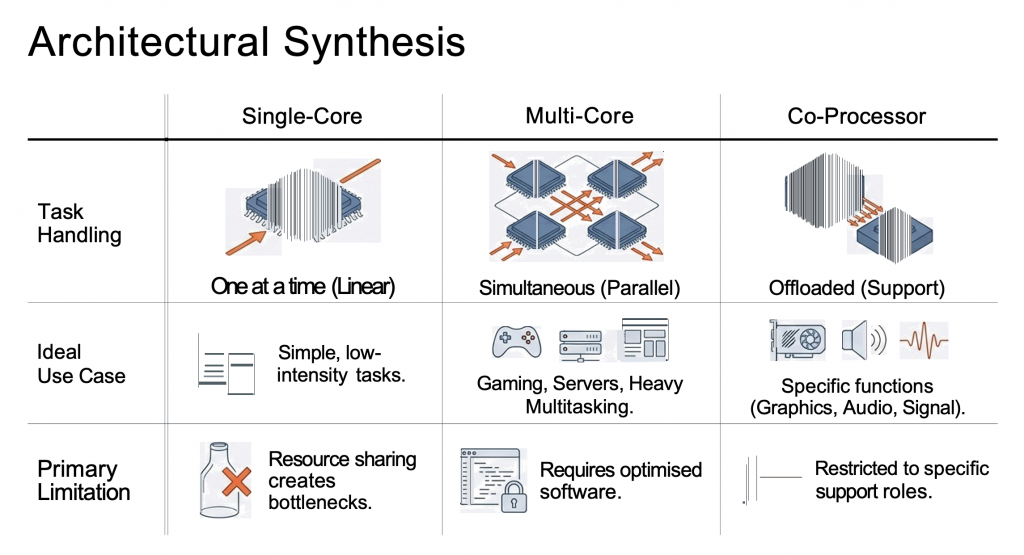




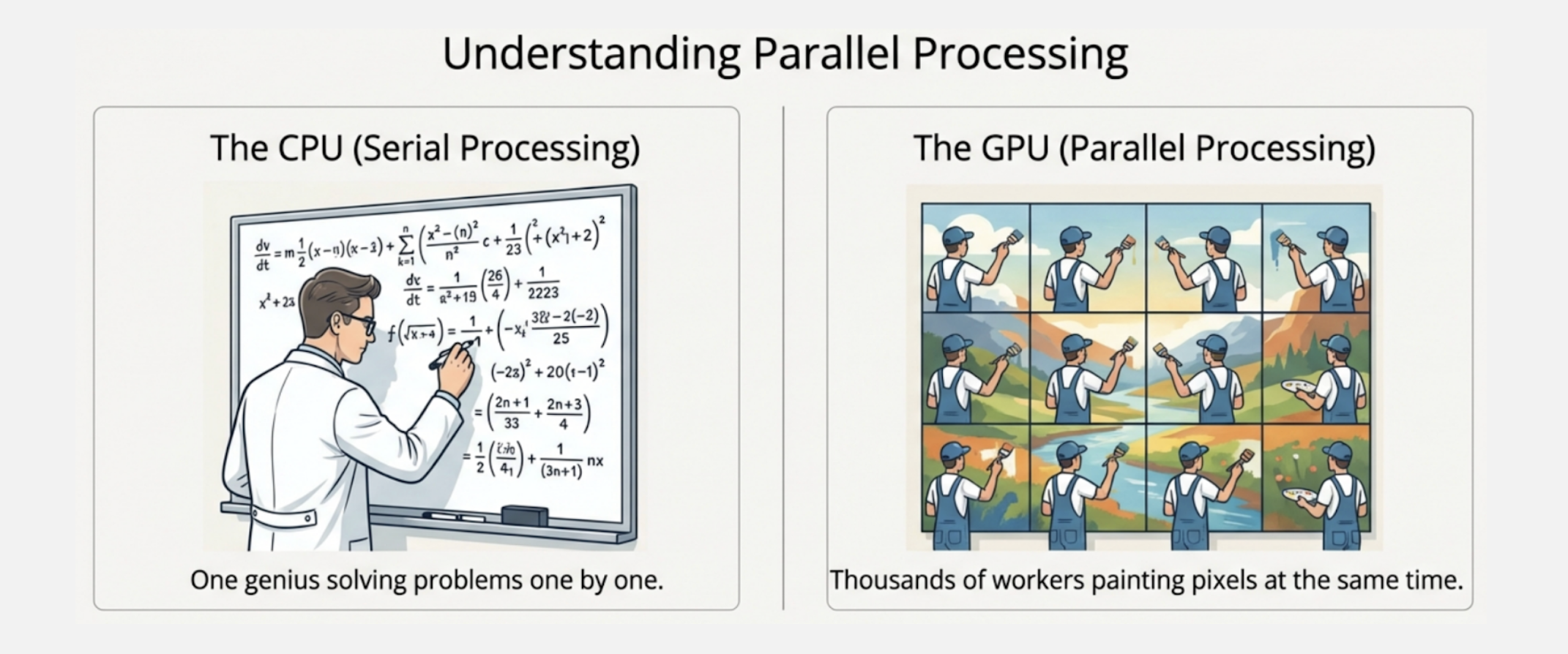





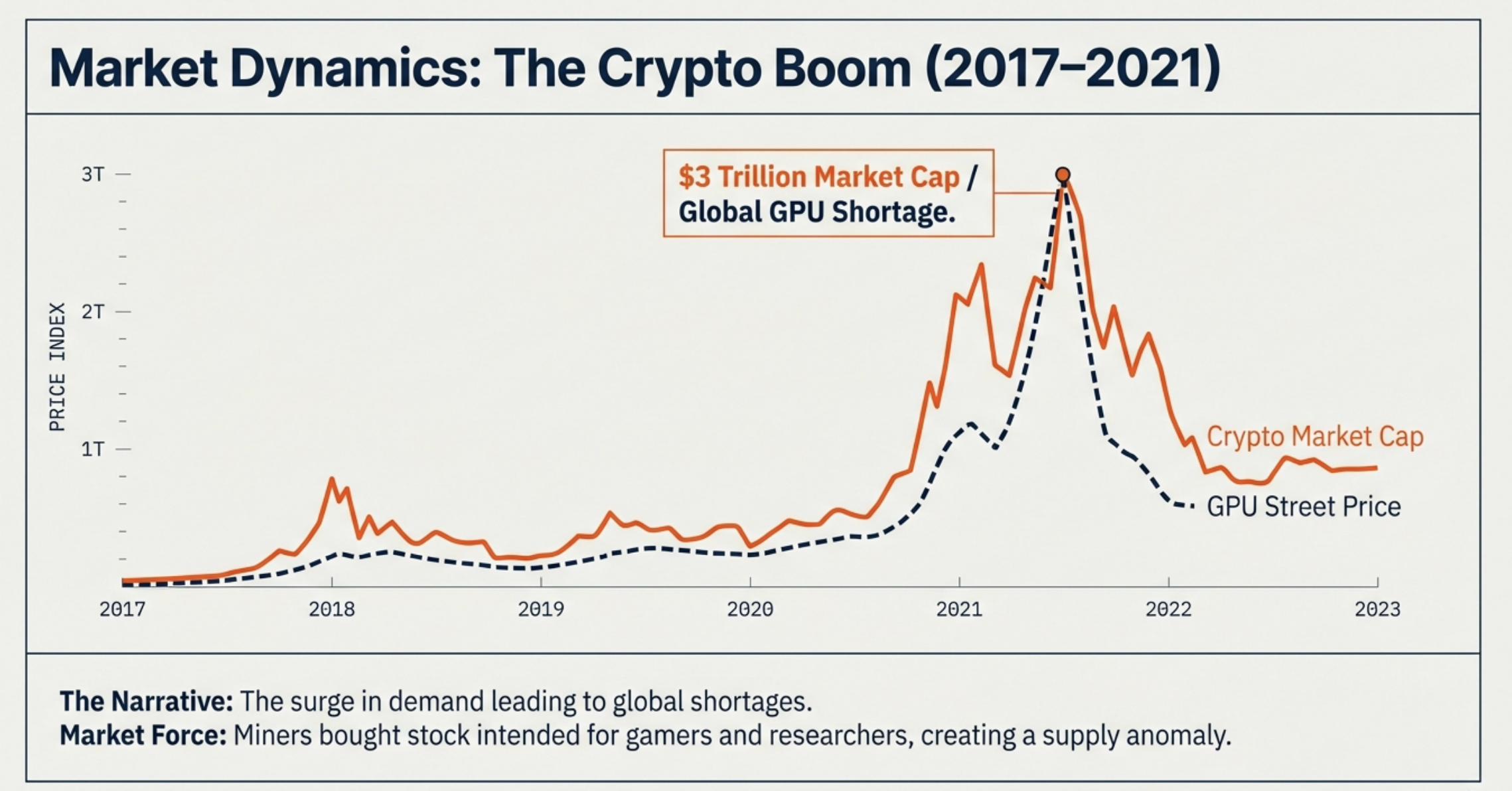
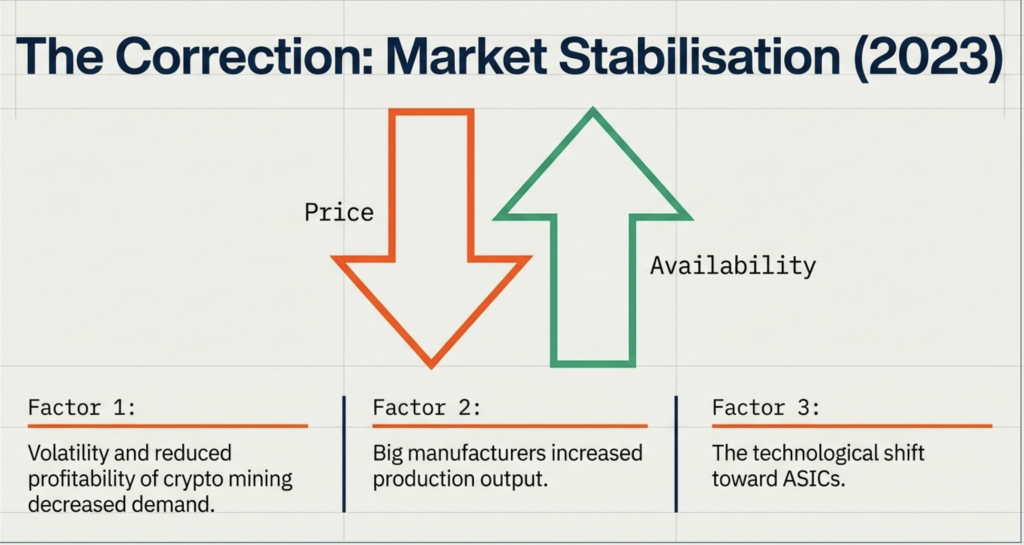

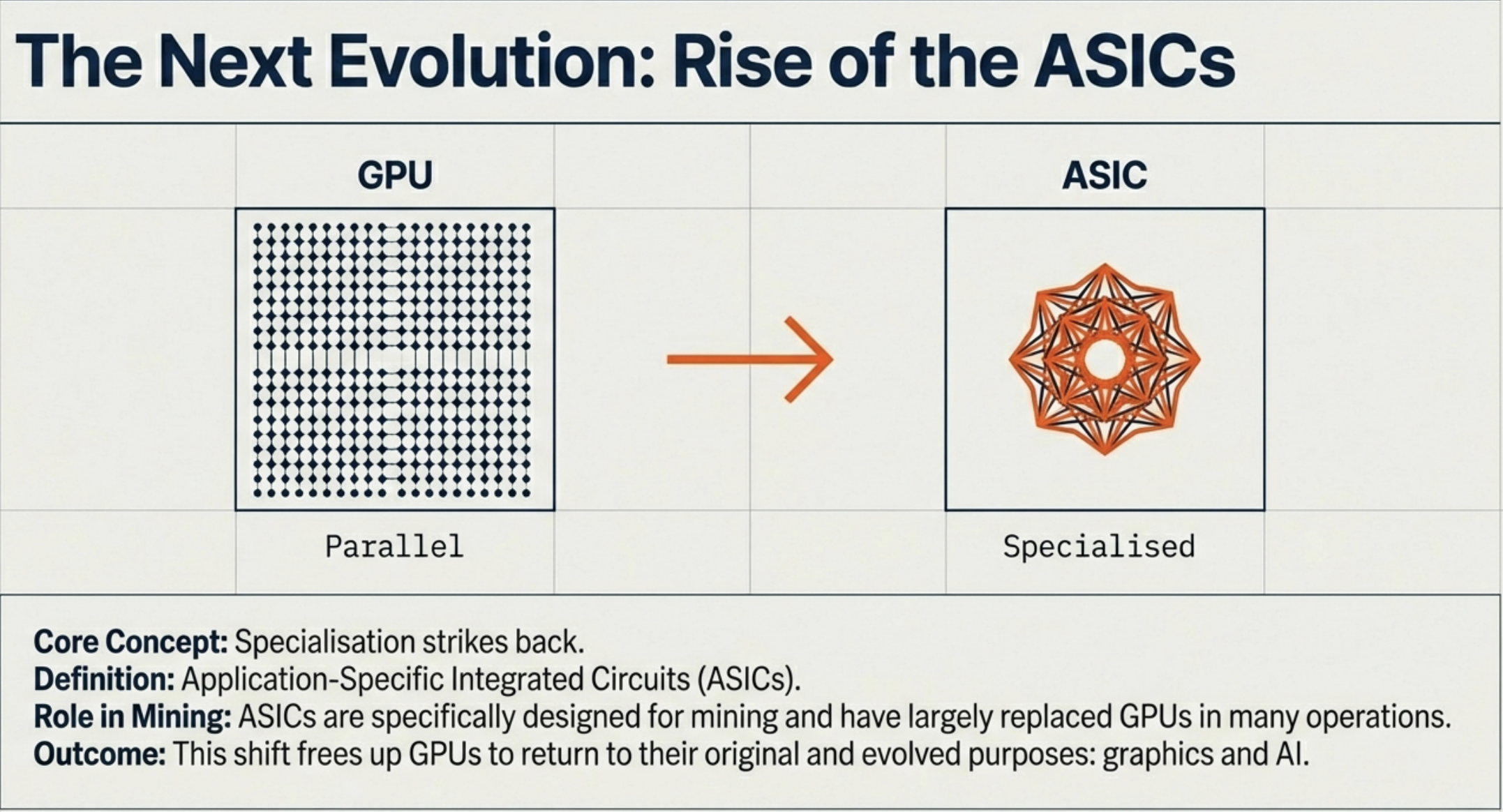
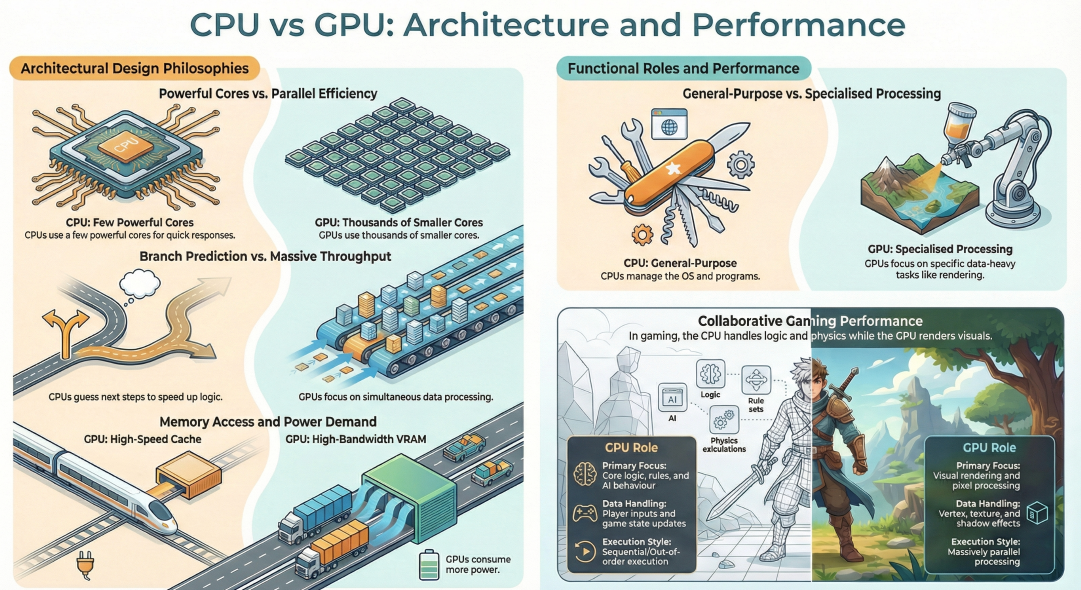
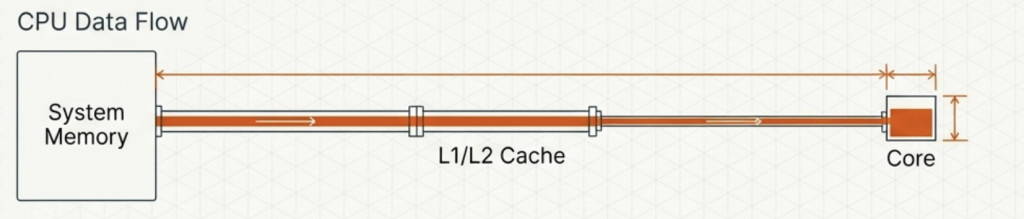
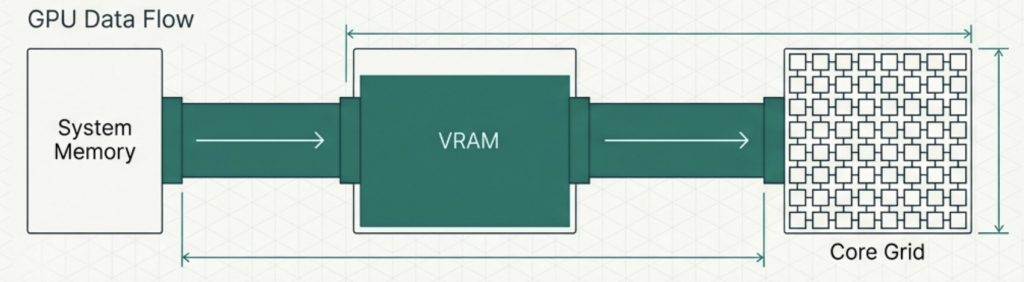


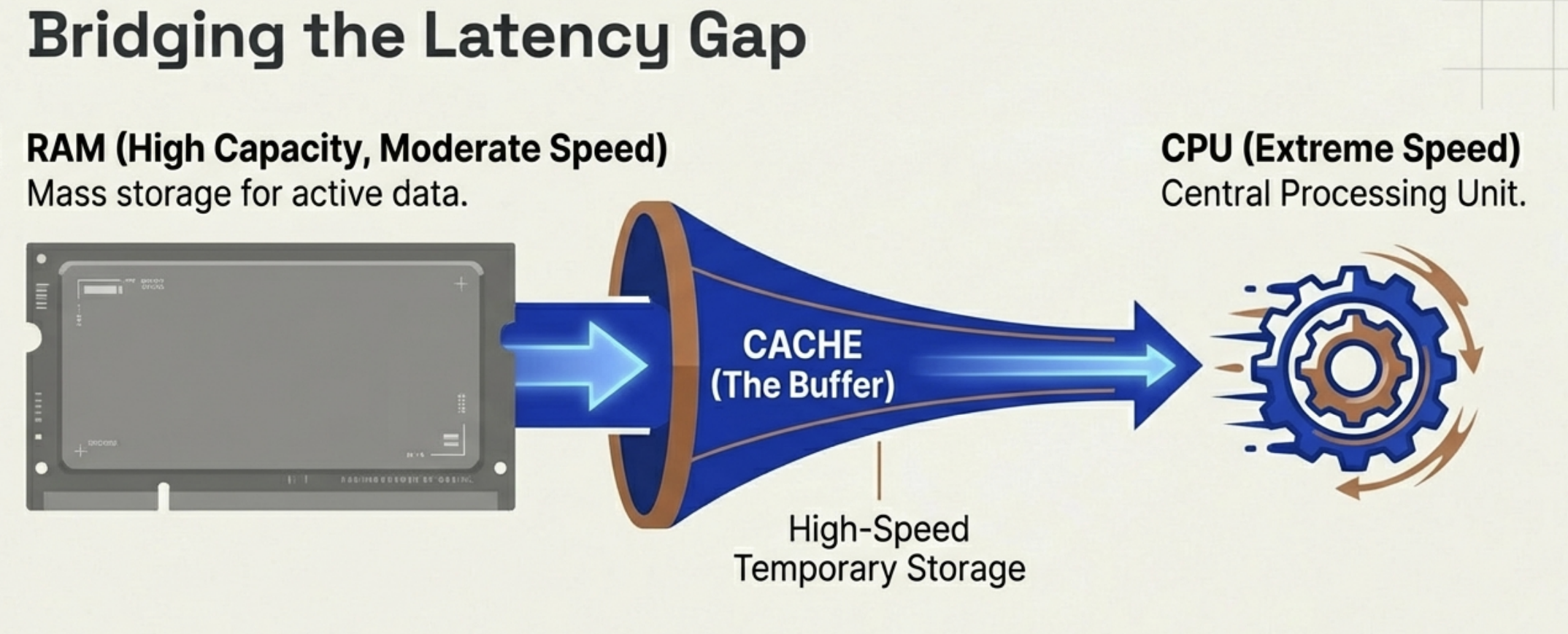
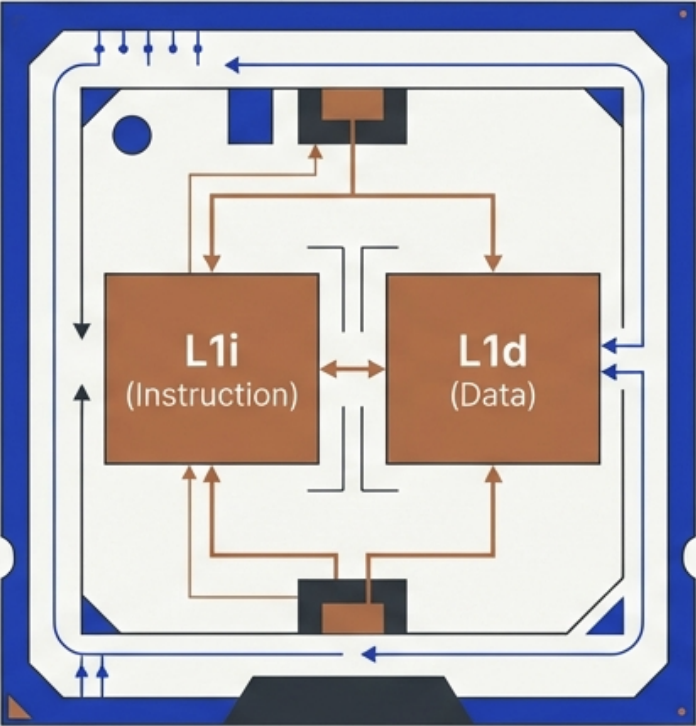
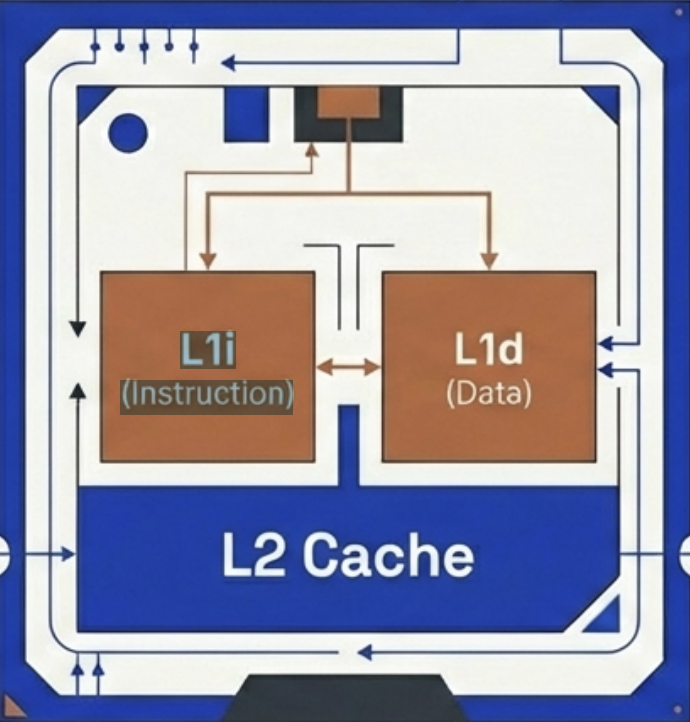
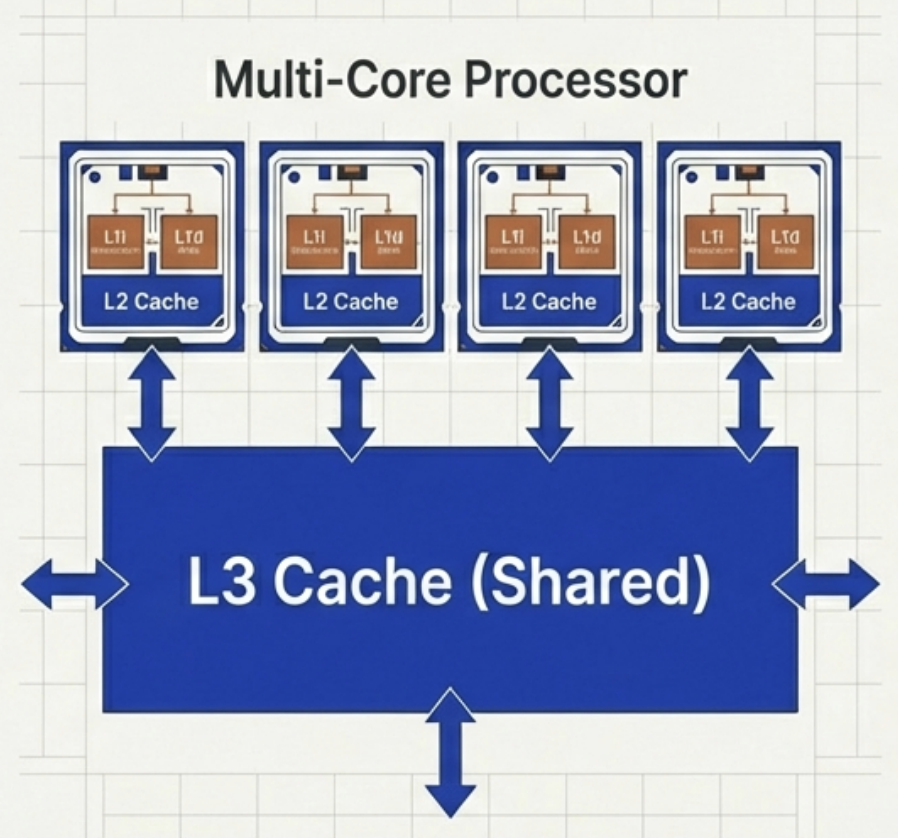
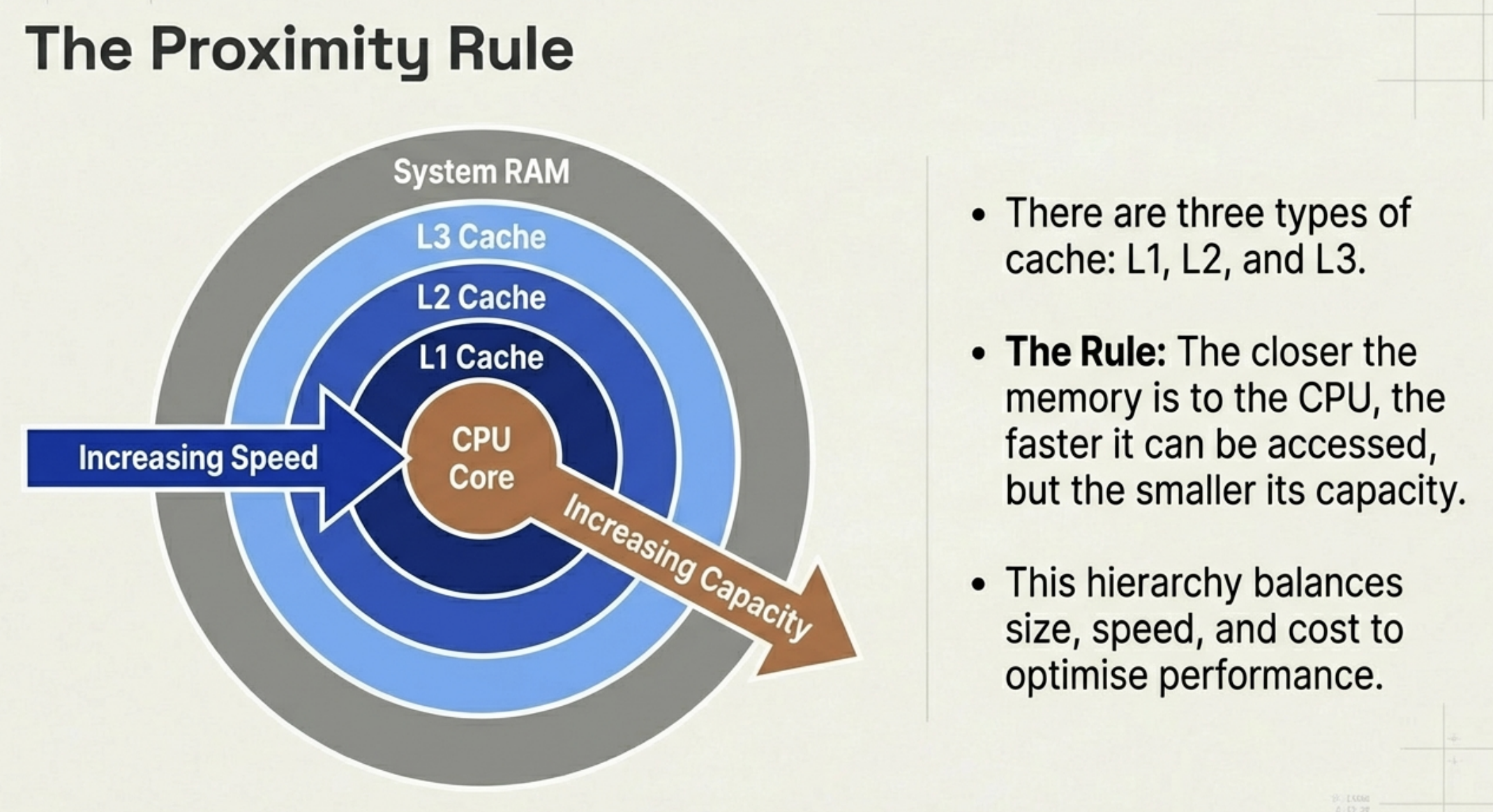
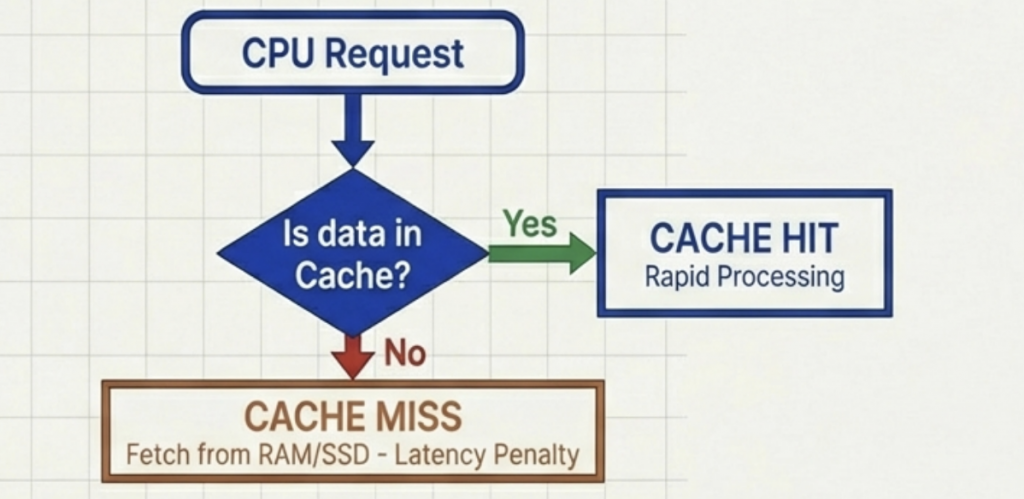
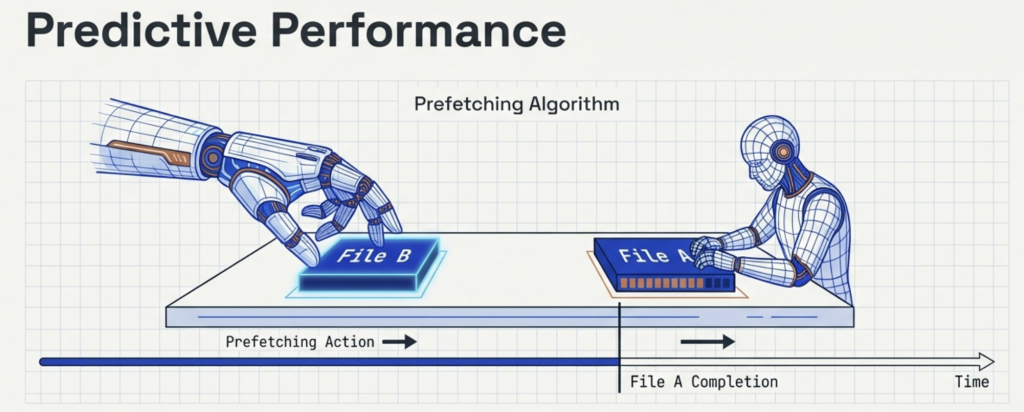

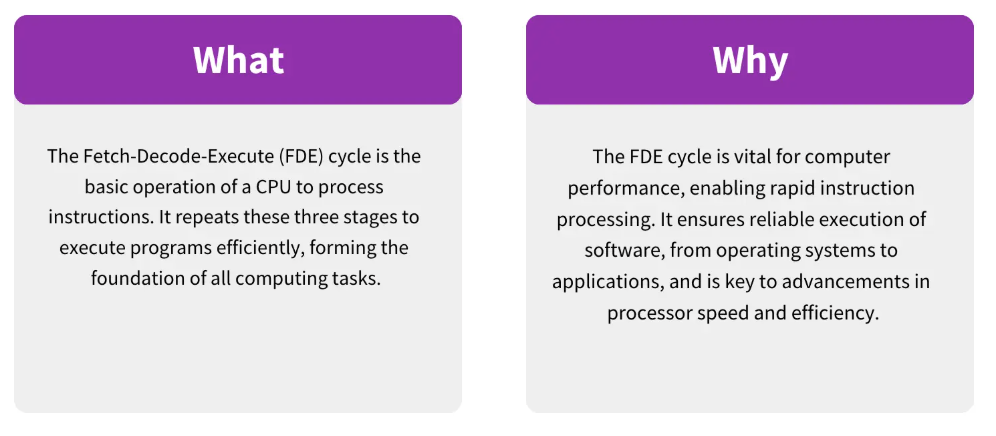
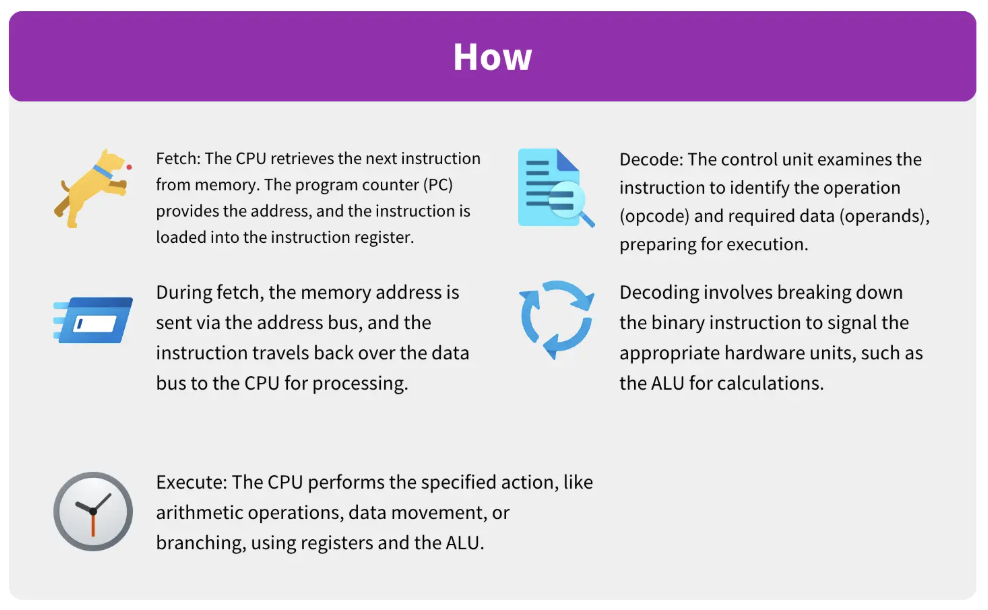
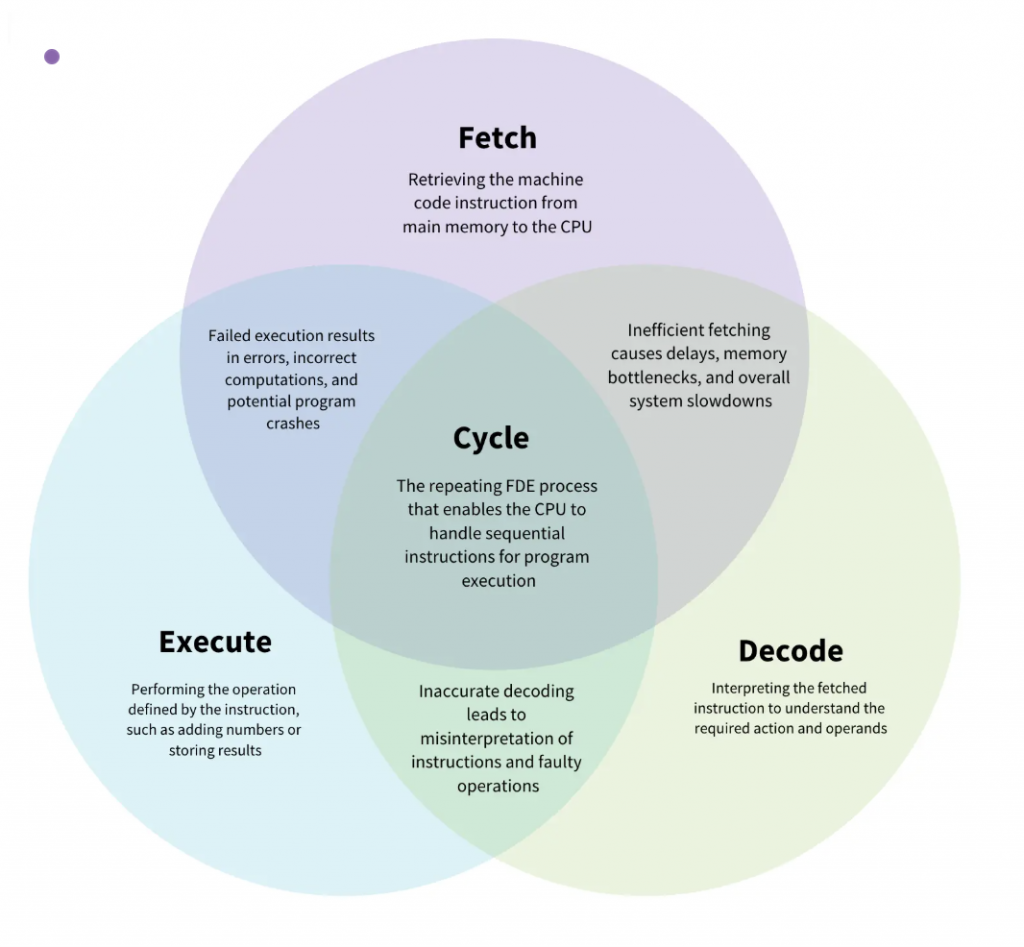
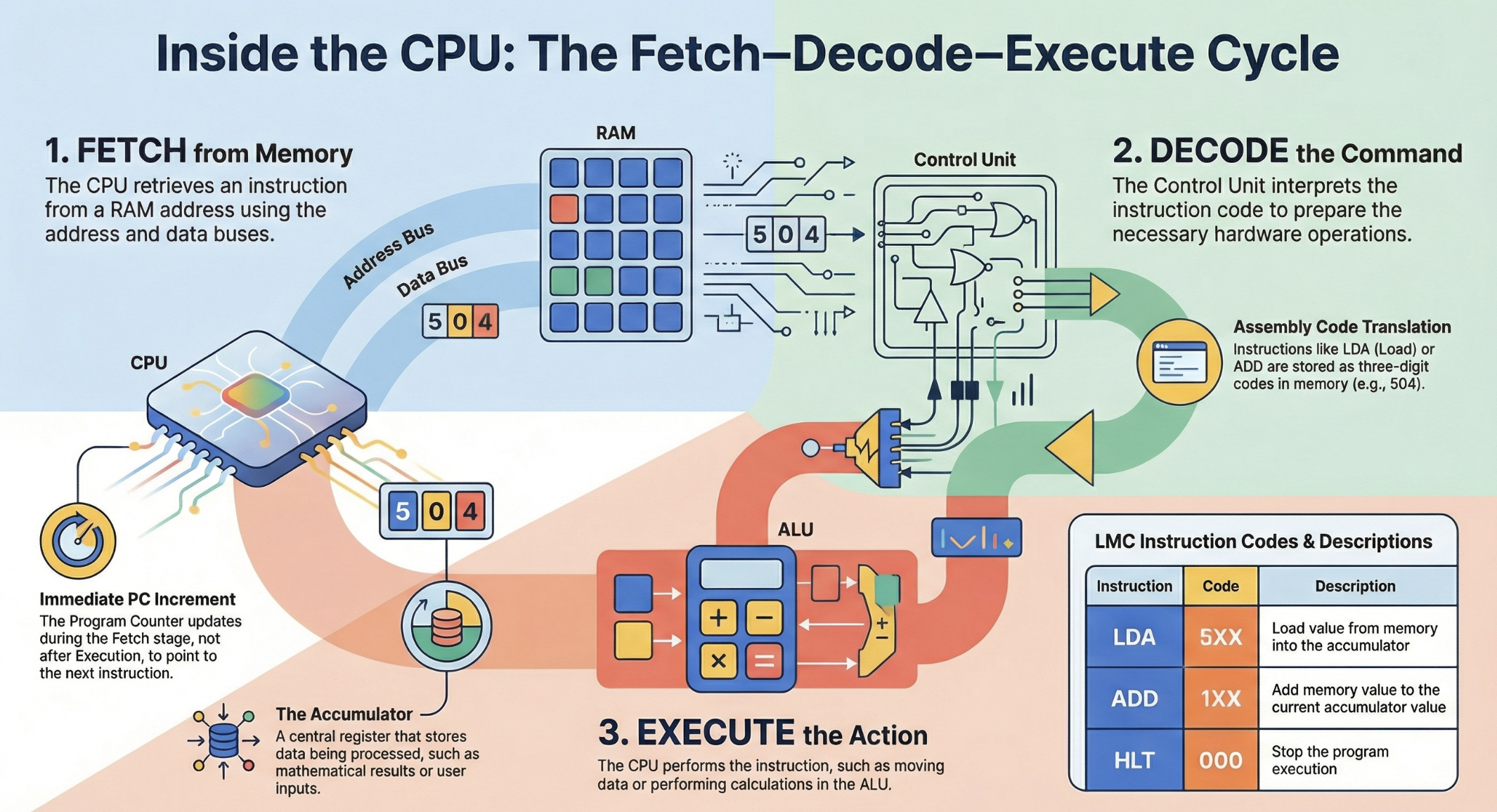
You can think of the FDE cycle as a chef in a kitchen. The Fetch stage is the chef grabbing a recipe from a book (RAM). Decoding is the chef reading and understanding the steps and gathering the necessary tools. Executing is the actual act of cooking the meal using the stove and pans (ALU and Registers). Pipelining is like having an assistant who starts prepping the next recipe as soon as the chef moves a dish to the oven, ensuring the kitchen never stops moving.